Storage and Retrieval
上一篇读书笔记,讲述了数据模型,而本篇笔记主要记录了这些数据模型是如何实现的,也就是存储引擎的实现原理.
数据库本质上就是要做两件事情,存储数据,提供查询.我们作为应用程序开发者为什么要了解数据库是如何存储以及如何查询呢?两个方面,第一,我们需要从众多的引擎中选择适合我们应用的实现,从而更好的实现我们的功能.第二,我们需要了解原理和机制,从而能够进行调优.
存储引擎从本质上来说,主要有两大类别:log-structured和page-oriented
一个简单引擎例子
通过bash实现一个很简单的数据库引擎.
#!/bin/bash
db_set () {
echo "$1,$2" >> database
}
db_get () {
grep "^$1," database | sed -e "s/^$1,//" | tail -n 1
}
数据的写入始终采用追加到文件末尾的方式,因此效率很高.磁盘的顺序读写吞吐量很可观
log用来指代顺序追加的记录序列
查询时则是顺序遍历每行数据,然后返回最新的数据行,因此效率不是很高.为了提高查询的效率,因此我们需要引入索引这个概念.索引通过保存一些额外的数据,加速定位我们需要查找的数据项.索引对于原始的主数据来说,是额外的记录信息,因此增加,修改或者删除索引,对于原始主数据是没有任何影响.
顺序追加文件是写数据的最有效的方式了,没有什么好的改进措施了.因此增加索引其实会降低写入的效率,因为在写入数据的同时,还需要维护索引信息.因此,我们必须谨慎选择索引,从而达到最佳的收益,平衡读写的问题.
Hash索引
针对KV数据库的Hash索引,是比较容易理解的索引结构,我们先从它开始认知索引结构.
Bitcask将全部的key以及对应的value位置,保存在内存中,作为系统的索引.因此这种引擎结构,比较适合针对某个key,有大量频繁更写操作的场景.
磁盘限制
我们上文的例子里,都只是往一个日志里追加内容,那么很容易导致文件越来越大,超过磁盘大小.因此我们需要优化我们的方案:
- 将整个log文件,划分成不同的段,每段限制大小.一旦超过大小限制,则追加到新的段文件中.
- 由于我们会追加重复的key值,因此可以通过compaction,合并相同key值,保留最新的value值.
- 通过compaction,段文件会变小,这时可以通过合并段文件,减少段文件的个数.
- 由于log文件是采用线性追加的方式,因此我们将合并的段文件内容,统一在后台写入到新的段文件里,读取操作还是读取旧的段文件.等到合并操作完成,我们使用新文件替换旧文件.
其他细节
| 问题 | 方案 |
|---|---|
| 文件格式 | 采用二进制安全的方式,而不是可阅读的格式 |
| 删除记录 | 给定key设置特殊的value值,来指定该key对应记录被删除 |
| 故障恢复 | 可以通过段文件,恢复索引值.或者实时持久化索引文件,来加速恢复 |
| 部分写 | 文件追加到一半挂掉了,Bitcask通过crc校验来保证数据的完整性和正确性 |
| 并发控制 | 这里采取的策略是只有一个写线程,然后文件只能追加,不能更删 |
追加文件而不是本地更新数据是不是有些浪费磁盘资源呢?实际上并不是:一来,对于硬盘来说,尤其是机械硬盘,线性追加写的效率要远远高于随机读写的效率.其次,对于追加操作,极大地简化了并发和故障恢复方案.最后,通过compaction(也是线性追加操作)操作,是可以释放磁盘空间,减少磁盘碎片的产生.
当然Hash索引也是有自己的问题的.首先,hash索引存在于内存中,因此如果你有很多的key时,内存容量会成为瓶颈.而如果使用磁盘来存储索引结构,就会造成大量的I/O操作,降低了查询速度.其次,hash索引只能用于单key的查询,无法支持范围查询.
SSTables和LSM-Trees
上文中说道,Hash索引无法进行范围查找,倘若我们能保证我们的key是有序的呢?由于我们是追加文件的操作,文件上无法进行排序,因此我们可以将排序工作放到内存中来.
优势:
- 在compaction的时候,即使文件超过了内存限制,因为文件内容都是有序的,因此可以采用多路归并排序.当遇到相同key时,由于文件有时间范围,取最新的文件内容作为最终的值.
- 在查找的时候,不再需要将全部的key都保存到内存里做索引.由于文件都是有序的,因此只需要保存每个文件的范围,然后直接跳到相关文件中查找就行了.也就是说我们只需要一个稀疏索引
- 针对部分作为整体被写入查询的记录,可以组合并压缩作为整体写入磁盘.这样极大的减少了I/O操作.
SSTable实现过程
- 当写入数据时,首先写入到内存中,内存中采用平衡树(跳跃表)结构保证key有序,该结构称为memtable
- 当memtable大于一定阈值后,memtable会被持久化到磁盘上,作为最新的SSTable,而且是有序的.新的数据,写入到新的memtable中.
- 查询的时候,先查询memtable,再依次按照时间新旧查询SSTable.
- 通过compaction来删除重新和删除的数据.
然而这里有个问题,就是一旦系统突然崩溃了,那么最新的写入memtable的数据就全部都丢失了.为了防止这个问题.
- 在写入内存数据前,顺序写入一个日志文件.当memtable持久化到硬盘后,删除对应的日志文件,为新的memtable准备新的日志文件.
这套体系最初来源于LSM-Trees.Lucene,ElasticSearch,Solor都采用相似的结构存储索引文件.
实现优化
- 由于查询操作需要多次查询,因此可以采用布隆筛,来确认一个key是否存在于数据库中.
- size-tiered:Hbase采用这种方式,新的小的sstable被合并到旧的大的sstable中.
- leveled: 每个sstable都很小,然后旧的sstable被放到下一层次中.
B-树
B-树基本上是关系型数据的标配引擎实现.
B-树是基于块或者页来实现的,通常是4KB或者更大.每个数据页通过物理地址进行标识,这些标识类似于内存里的指针.任何key的查找,都需要从B-树的根节点进行查找.每个叶子节点包含一些key和标识,这些标识中间的key值,代表了这些标识指代的key值空间范围.叶子节点里,往往包含有具体存储的数据,或者真实数据存在于哪个页中.
具体实现时,B-树的分支系数往往高达好几百.并且当进行数据更改时,直接找到数据页的位置,然后本地进行修改,之后再写回磁盘.为了防止数据崩溃,导致更改丢失,需要在写入页之前先写入write-ahead log(也叫作redo log),这也是一个只允许追加的文件.
实现优化
- 一些数据库采用写时复制的机制,而不是写入redo log重写数据页的方式.
- 为了节省页空间,可以不用保存全部的key值,只要提供足够的信息能说明key值范围就行.减少key值大小,使得一个页空间能存更多的key值范围.
- 尽量保证叶子节点的数据页在磁盘上是顺序的,因为很多时候,需要读的数据范围,可能包含多个叶子节点,顺序的读有利于提供效率.
- 每个叶子节点和兄弟节点相连,这样在顺序扫描key值时,就不需要再从根节点查找了.
- 使用分形树索引,分形树索引和B-树很像,不同点在于,每个节点附带有一个缓存队列(FIFO队列),队列里包含了所有的写操作.因此分形树写入很快,只需要将操作追加到缓存队列里.而读的时候,需要将从根节点到叶子节点上的缓存队列操作都执行完毕,才会返回结果.
B-树和LSM-Trees
一般来讲,LSM-Trees写入更快,而B-树读取更快. SSD硬盘采用log-structured算法,将随机写变成顺序操作,因此两种写入模式影响不是特别大.但是在有限的磁盘带宽下,较少的写入以及减少磁盘碎片仍然还是有优势的.
| 优势 | 劣势 | |
|---|---|---|
| LSM-Trees | 磁盘利用率更高 | 1.写入放大,由于compaction和merge的机制.写磁盘的次数越多,在有限的磁盘带宽下,每秒的写入数量越少. 2.compaction操作会阻塞正常的读写操作. 3. 当写入的速度大于compaction的速度时,就会导致磁盘大量被占用,查询速度变慢. |
| B-树 | 运行极为稳定 | 1.数据写入必须写入两次,一次写入redo log,一次写入数据页. 2.会产生磁盘碎片 |
辅助索引
由于辅助索引里存在多个kv值,因此两种方式实现:
- key对应一个value的list
- 为key增加一个唯一标识来保证唯一性.
辅助索引实现
我们在建立索引的时候,key是用来查找,而value可以包含两种值:一种是实际的数据行.另一种是数据行的引用,在这种方式里,数据行所在的文件被称为heap file,数据行不需要特定的顺序,可以是追加写入的,也可以保存删除数据的记录.后一种方式的好处是,数据始终存储在原地,而我们可以建立多个索引,每个索引值都指向同一个位置.
当更新一个数据的时候.如果新值不大于旧值,我们可以直接在heap file上进行原地修改,索引文件都无需修改.而当新值大于旧值时,要么我们需要更新所有的索引,要么原来的旧值变成一个指向新值的引用值.
从索引再到实际记录,很影响读的性能,因此最好能直接存储数据行,这被称为clusterd index,而辅助索引的值都只是保存聚合索引使用的主键.还有一种索引,介于两者之间,被称为covering index或者index with included columns,这种索引的值只保存了部分数据列.不管哪种索引,都能加速我们的查询,但也给我们的写入带来了格外的工作量.
多列索引
多列索引(concatenated index),其实就是把多列值按序追加组成一个key来建立索引.
全文查找与模糊索引
Lucene存储的时候,使用了一种类似SSTable的结构.但索引则是采用类似字典树的结构.
内存数据库
有很多内存数据出现.为了防止服务崩溃数据丢失,可以采取如下措施:
- 使用特殊的硬件(有电池供电的内存)
- 将更改日志写入磁盘.
- 将快照写入磁盘.
- 备份内存状态到多台服务器.
虽然会写入磁盘数据,但是内存数据库只是用磁盘来备份数据,读写操作还都是基于内存的.内存数据库的读写速度远远高于磁盘数据库,这并不是因为他们都是基于内存操作,实际上由于操作系统会缓存磁盘块,因此实际上很多时候磁盘数据库的操作也都是在内存里.主要的速度差距来自于,内存数据库不需要将数据编码成可以持久化的格式.
由于基于内存,所以内存数据库可以提供更加丰富而强大的数据结构.通过磁盘交换,内存数据库可以存储远超过内存大小的数据,这种方法叫做anti-caching,在适当的时候将内存数据缓存到磁盘上.这类似操作系统的虚拟内存原理,但是数据库可以比操作系统更有效的管理内存.不过,这种方法仍然要求索引文件必须小于内存限制.
OLTP与OLAP
| 属性 | OLTP | OLAP |
|---|---|---|
| 主要读模式 | 每次查询都是少量数据,按照key进行查询 | 汇集大量的记录数据 |
| 主要写模式 | 随机写入,来自用户的输入数据 | 批量导入或者事件流 |
| 主要用途 | 终端用户,web应用 | 内部分析使用 |
| 数据需求 | 数据的实时状态 | 历史数据 |
| 数据规模 | GB | TB |
数据仓库
数据仓库作为独立的系统,不会影响OLTP系统的操作.数据仓库的数据都是来自各个OLTP系统的只读数据,并被转换成分析有好的格式,然后加载到数据仓库里的.这个过程被称为ETL(Extract-Transform-Load).将数据仓库独立处理,可以很好被优化从而更有效的进行数据分析.
数据仓库通常都是关系型数据库,因为sql很适合做分析使用.虽然都提供sql查询,但是数据仓库和OLTP数据库的内部实现是不同的,都为了更好的提供各自领域的功能,做了不同的调整和优化.
数据仓库的Schema
star模型是最常用的模型,一般都是一个fact表在中心,然后dimension表在周围.类似星状.
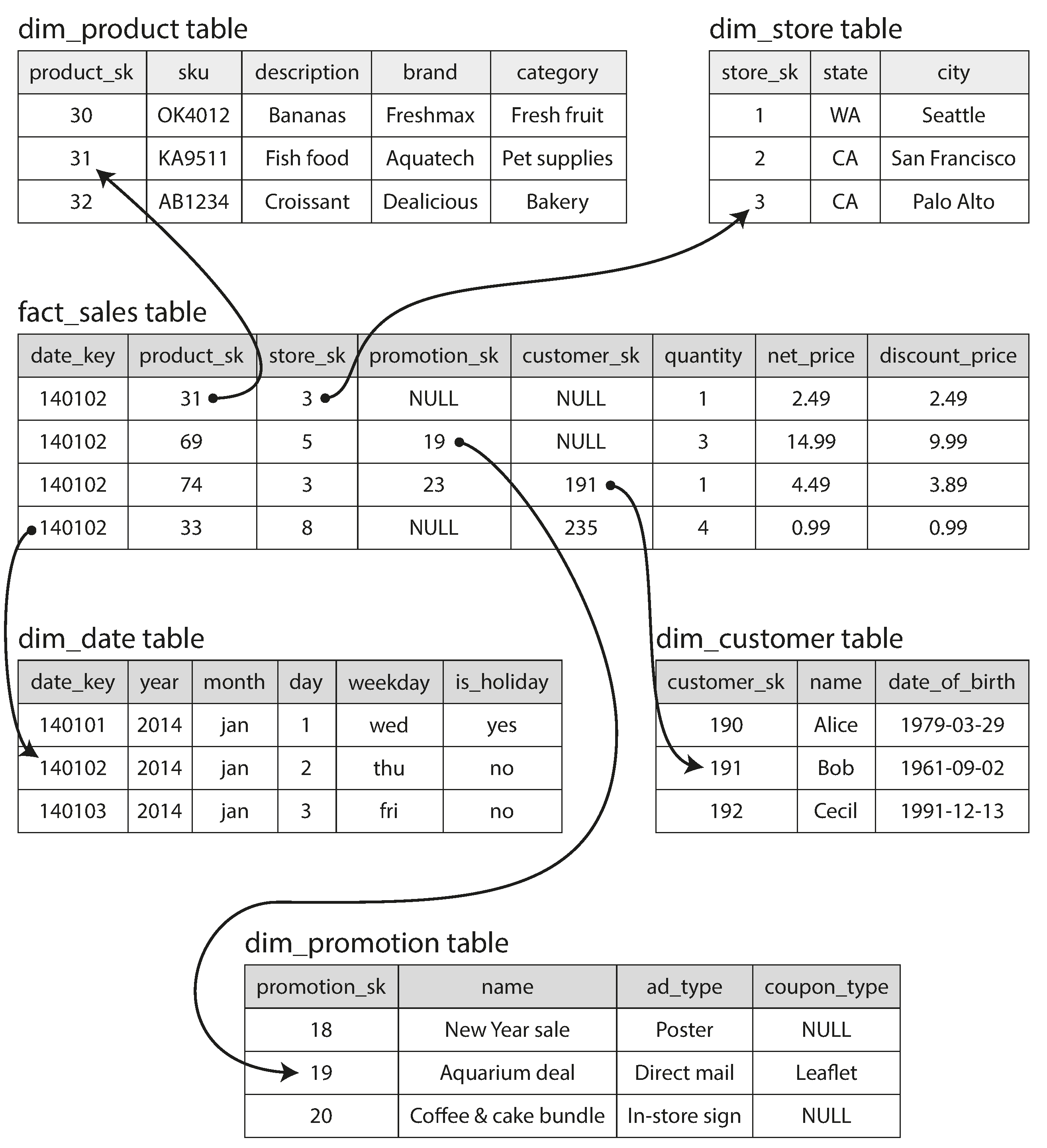
与star模型类似的叫做雪花(snowflake)模型.雪花模型里,dimension进一步被分割成subdimensions.而星状模型更简单更容易用来分析处理.无论哪种模式,基本上都是以大宽表的形式进行存储.
列存储
在数据仓库里,中心表可能会有上亿行数据,pb级别的数据量,因此存储和查询都是个大问题.而周围的表则要小得多,因此我们需要想办法处理中心表的问题.事实上,虽然中心表很宽,但每次我们查询和分析时往往只关心部分列数据,而不是全部数据.
传统的OLTP数据库都是行数据库,所有数据一行一行的存储.在处理查询部分列数据的问题时,仍然需要将一整行数据查询加载到内存里,然后再处理过滤,返回我们需要的列.而列数据库则是将一列一列的数据存到一起.列结构需要保证每个列文件里数据的排序必须和数据行是一致的,在查询某一行数据时,就需要分别从列文件里查询对应顺序的数据,然后组合成这一行数据.
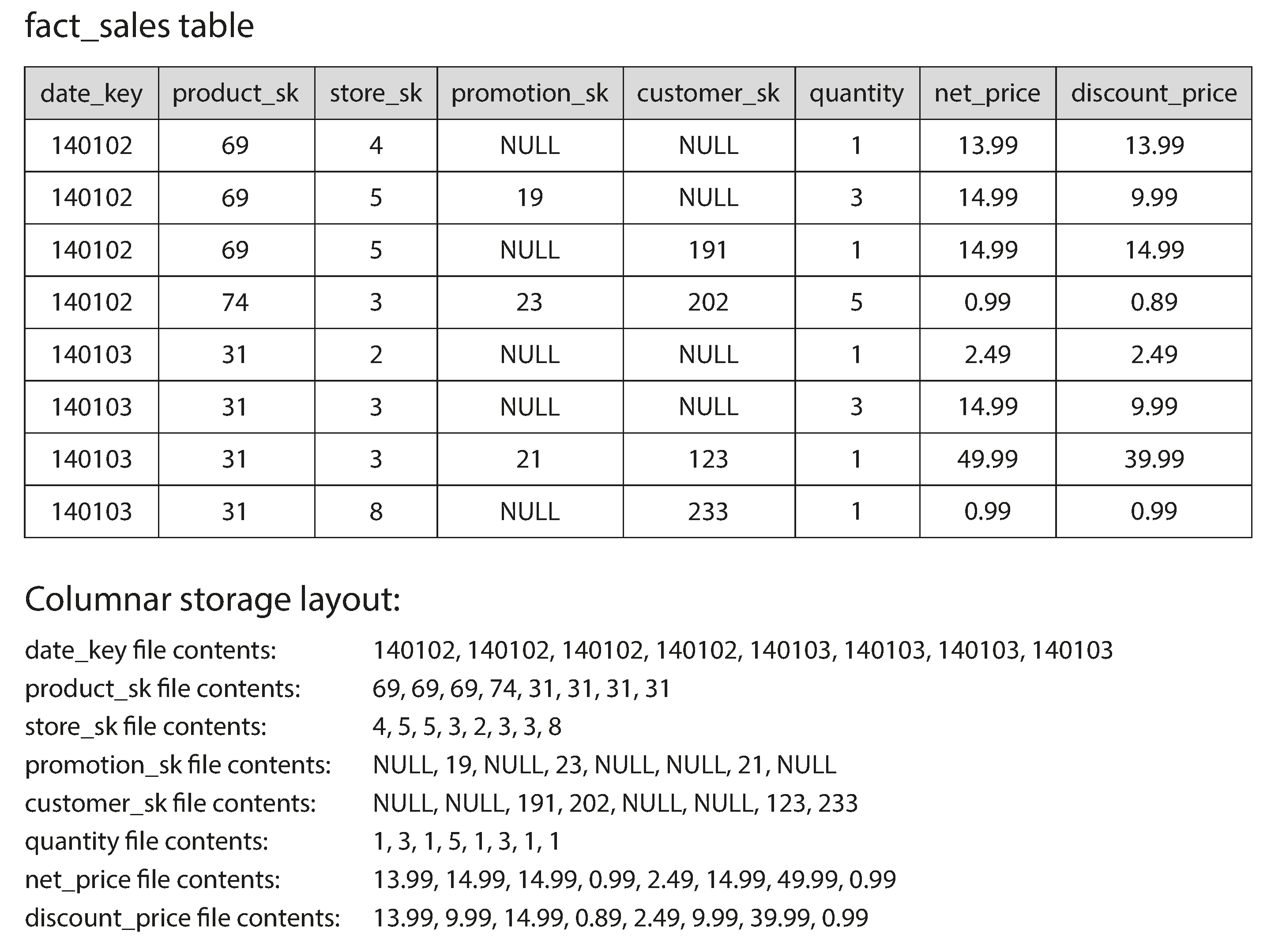
列压缩
除了减少加载的列数,还可以进一步压缩数据来增加磁盘的吞吐量.由于每一列的数据类型是一致的,因此可以根据不同的数据特征选择压缩方式.在数据仓库里最常用的压缩技巧就是bitmap encoding.通常来说,一列中存储的不同数据个数远远小于数据行数.当不同数据个数很小时,我们的bitmap只需要很小的位数.而当个数较大的时候,意味着0值很多,这个时候我们可以使用run-length编码.
Hbase实际上不是列存储数据库,因为Hbase存在column families的概念,在一个family里,数据还是按照行存储的,并且附带着行键,而且也不进行列压缩.
数据仓库在查询时,往往需要查询海量的数据,因此磁盘带宽是一个很大的瓶颈.除了这个,cpu缓存带宽也是问题,因此需要减少分支错误和bubbles,并且充分利用cpu的SIMD能力.
列存储和压缩减少了从磁盘读取的数据量,提高了磁盘的吞吐量.压缩的数据可以加载到L1缓存里进行遍历,这里没有函数调用,比代码里处理的效率搞多了,压缩的数据也使得更多的数据行可以加载到L1缓存里.此外压缩的列数据可以直接进行位操作.这种操作被称为矢量处理.
列存储排序
由于要求每一列数据拥有和行一致的序列,因此数据的有序性需要管理员提前设定.需要根据经验,把最经常用来查询的列作为第一排序列,当然也可以指定第二排序列,第三排序列.排序除了方便查询,还能够提高压缩的效率.当第一排序列没有多少不同值时,排序使得相同的值排在一起,因此使用简单的run-length编码,可以得到很高的压缩率.尽管这可能会使得第二第三排序列变得混乱,但第一排序列极大得到压缩也是值得的.
列存储写入
列存储的写入,需要类似LSM-Trees,所有的数据先写入内存中,然后再持久化到磁盘上,并通过合并写入新的文件.查询的时候,也得先查询内存,再查询磁盘.
数据魔方与物化视图
由于在做数据分析时,常常会需要一些聚合结果.可以将这些聚合结果持久化成为真正的表格.由于聚合结果需要被更新,因此这使得写入操作变得更加复杂,但是这种物化后的视图,能极大的提高读能力.
总结
OLTP总是面向用户的,因此会有大量的请求.通常针对每次请求,应用程序只涉及到少量的数据,并使用索引键来查询数据.磁盘的寻道速度通常是这类应用的瓶颈.
数据仓库以及其他相似的数据系统,通常大量应用于公司的商业分析上,而不是面向终端用户的.这类系统的请求量并不大,但每次请求都涉及到海量的数据,因此磁盘的带宽是这类应用的瓶颈.因此列式存储逐渐成为流行的解决方案.
OLTP数据系统通常有两类引擎:
- log-structured类,只允许追加和删除文件,但不允许更新文件内容.
- update-in-place类.将磁盘看做可以覆盖的数据页集合.B-trees是关系型数据库主要的引擎实现.