Reliable, Scalable, and Maintainable Applications
数据密集型应用特征: CPU能力很少是这类应用的限制因素,反而是数据量,数据的复杂度以及数据的变化速度.
数据密集型应用通常是由多种通用功能模块组合而成,这些功能包括:
1.数据库
2.缓存
3.索引
4.流处理
5.批处理
而不同的数据库系统提供不同的功能特征,因此当我们建设数据密集型应用时,我们需要根据需求和环境来选择不同的数据库系统,组合它们来达到我们的目标.
数据系统
我们统称这些功能模块是数据系统.
- 如今新涌现的数据库或者数据处理系统,趋向于提供多样化的功能,因此数据库也好,消息队列也好,他们之间的界限越来越模糊了.
- 单一的数据工具已经无法满足我们的应用需求,我们需要使用不同特性的数据工具,然后依靠我们的应用代码把它们组合起来.
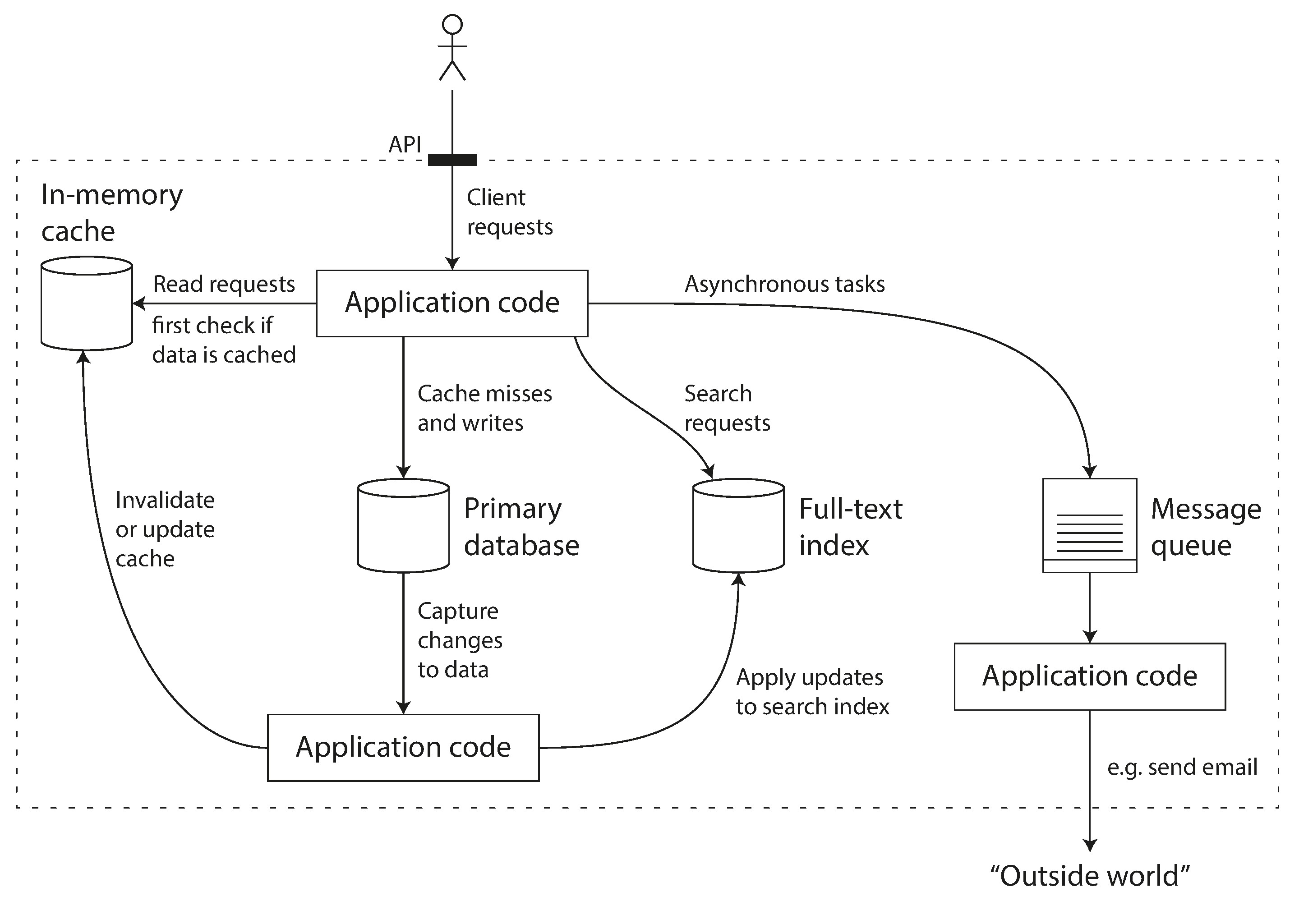 例如,当你的应用使用了缓存(memcached),也使用了全文搜索工具(elasticsearch或者solor),然后还是用了传统的数据库(mysql).这种场景下,你的代码必须要负责同步这几个数据系统间的数据.之后你导出的应用API,实际上赋予了这三种数据系统之外的功能,你的api能保证你的应用数据同步一致,因此你就构造了一个新的数据系统.
例如,当你的应用使用了缓存(memcached),也使用了全文搜索工具(elasticsearch或者solor),然后还是用了传统的数据库(mysql).这种场景下,你的代码必须要负责同步这几个数据系统间的数据.之后你导出的应用API,实际上赋予了这三种数据系统之外的功能,你的api能保证你的应用数据同步一致,因此你就构造了一个新的数据系统.
数据系统核心概念
关键点
- 可靠性(Reliability): 系统应该能够持续不断地,无论在何种情况下(软硬件错误,或者人为错误),正确并且有效的工作.
- 可扩展性(Scalability): 随着系统增长(数据量,流量,复杂度等),系统能够应对这种增长.
- 可维护性(Maintainability): 随着时间,无论是维护这个系统的运维人员,还是为系统增加新的功能的开发人员,系统必须能够让他们能够高效的工作着.
可靠性
可靠性,简单来说就是系统能够正确地运行,即使遇到了故障(fault).如果一个系统能够预期到故障并准备好了应对措施,那么我们称该系统具有容错性(fault-tolerant),或者弹性(resilient).当然容错也是要有限度的,这里的容错是指一些特定类型的故障.
故障和失败(failure)是有区别的,故障往往是指系统的一部分的运行偏离了预期,而失败则表示系统无法提供服务了.设计良好的容错机制可以防止由于故障导致的服务失败.有时候,我们设计了容错机制,我们可以故意杀死系统某个进程,来人工引入故障,从而来检验我们的容错机制是否发挥了作用.Netflix公司开源的Chaos Monkey就是这样一款工具.
硬件故障(Hardware Faults)
硬件错误包罗万象,包括硬盘故障,内存条毁坏,断电,网络设置错误等等.
冗余:RAID配置防止硬盘故障,服务器双电源防止断电,热切换CPU防止cpu错误,机房的备用电源.冗余并不能让阻止硬件的故障,但能够让我们的服务持续地工作着. 因此针对相当重要需要高可用的应用,我们会使用多机器冗余.
但是随着机器使用数量的增加,硬件故障越来越多,因此现在有种趋势就是倾向于软件容错,而不是进行硬件容错.
软件错误(Software Errors)
由于bug导致的一系列服务故障.
bug故障很难避免,因此需要开发者付出更多的注意来尽量减少bug的出现.
人为错误(Human Errors)
人为的操作失误,是导致停服的主要原因,而硬件故障只占了10-25%.可以从以下几个方面来加强系统:
- 设计系统时,控制API的行为.
- 利用沙盒技术,将用户行为与系统进行解耦.
- 系统需要充分的测试.
- 设计机制,能够快速的从人为错误中恢复系统.
- 遥感技术,收集服务指标.
可扩展性
可扩展性是用来描述服务应对负载增长的能力.
负载
负载参数用来描述系统的负载情况.包括每秒的请求数,数据库的读写比例,同时在线人数,缓存的命中率等.
性能
可以从两个方面来看待性能:
- 当负载参数在增加的时候,保持可利用资源不变,你的系统性能会受到什么影响.
- 当负载参数增加的时候,你需要增加多少资源才能满足你的性能要求呢.
性能指标通常有: |性能指标|应用| |-|-| |吞吐量(throughput)|在批处理系统中,例如Hadoop里,每秒系统能处理的记录数,或者在固定数量的数据上,运行一个任务所消耗的时间| |响应时间(response time)|在线系统,通常我们关注客户端发送请求,到接受请求的时间间隔| |时延(Latency)|时延包括网络时延,以及处理请求的排队时延| |数据分布(distribution)|我们观察一次响应时间没有意义,通过观察多次的分布比较有意义| |平均数(average)|一般是指算数平均数| |百分位数(percentiles)|中位数(median)是指中间的观测指标值,长尾延迟(tail latencies)也很重要.| |pn|n从0到100,意味着一次请求,有n%的概率符合某种要求| |SLOs(service level objectives) and SLAs(service level agreements|约定了服务期望的性能与能力|
可扩展性如何达成
首先,需要明确,单一的架构的设计是不现实的.尤其是当你的服务数量级一直在不停增长时,你的架构必须不停的变化.可扩展性往往包好纵向扩展(使用更强大的机器)和横向扩展(增加更多的机器),一个好的架构设计一定是混合使用两者进行设计的.
将系统设计成弹性可扩展的(即能够根据负载自动扩容)固然是很好的,但很显然人工配置扩容更加容易也更少出错.
对于无状态的服务,横向扩容很明显有很大的收益.但是对于像数据库这样的服务,横向扩容会导致额外的复杂度,因此除非迫不得已,尽量进行纵向扩容.当然,随着分布式系统设计的越来越好,分布式数据系统将会成为一种趋势.
可维护性
众所众知,一个系统最大的消耗不是开发阶段,而是修bug,运维系统,排查错误,升级系统,增加新的功能等等.
为了设计出具有可维护性的系统,我们需要遵守三个原则:
- 可操作性: 使得运维人员很容易就运行系统.
- 简单化: 尽量设计的系统要简单容易理解.
- 可扩展性: 系统设计的要尽量容易让人去更改或者添加新的功能.
可操作性
良好的操作,通常能够突破设计不良的软件带来的限制.但是一个设计良好的软件,未必能在不良好的操作环境下正常运行.
良好的操作包括:
- 监控系统健康,一旦发现异常能够快速恢复服务.
- 能够追踪系统的异常原因.
- 保证软件平台时刻更新.
- 密切关注系统间是如何相互影响的.
- 预期未来可能发生的问题,在他们发生前进行解决
- 建立工具来部署和配置化服务.
- 执行复杂的运维活动,例如将服务从一台服务器迁移到另一台服务器.
- 当配置变化时,要保证维持系统的安全性.
- 定义一些流程,来帮助保证生产环境的稳定性.
- 维护系统的知识,保证人员流动不影响系统的维护.
对于数据系统而言,以下是特定的良好操作行为:
- 可视化系统的内在运行状态,时刻监控系统.
- 利用标准化工具,提供自动化集成.
- 避免对某台机器的依赖.
- 提供好的说明文档和易于理解的说明方式.
- 提供好的默认行为,从而有必要时,让管理员恢复默认值.
- 设计适当的自我修复机制,也给管理员手动恢复的机制.
- 系统运行都应当表现出可预测的行为.
简单化
通过抽象(abstraction)来将复杂逻辑从系统移除,从而简化系统的设计.
可扩展性
通过敏捷开发,来适应软件的快速变化.
总结
有用的应用被设计出来需要满足各种需求,包括功能需求(存储,检索,查询,处理数据)和非功能需求(安全性,可靠性,可扩展性,可维护性等等).
可靠性意味着,即使发生了故障系统也能正确运行.故障包括硬件故障,软件故障和人为故障.通过容错性机制来规避一些类型的故障.
可扩展性意味着,即使系统负载增加,我们仍有策略能够保证我们的性能.
可维护性内涵比较多,我们通过抽象化和良好的运维机制来达到需求.